type
Post
status
Published
date
Jul 11, 2022
slug
weekly-ner
summary
弱监督命名实体识别实践
tags
NLP
NER
category
技术分享
icon
fas fa-link
password
URL
任务描述
命名实体识别(Named Entity Recognition,简称NER),又称作“专名识别”,是指识别文本中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等。本文主要介绍影视综艺、音乐垂直领域下的NER任务。
视频内容平台上,用户的作品包括视频、封面和标题。其中标题出现在作品的第一次曝光的场景,蕴含着大量用户想表达的信息,因此准确地理解作品的标题能够提高用户的搜索体验。其中,通过NER对标题进行标签化是一个有效的手段。
主要挑战
- 在用户生成内容平台上,由于是用户产生的内容质量参差不齐,标题口语化比较严重。
- 领域实体存在歧义。影视、音乐作品通常与日常用语或者其他领域实体重名,导致误召回严重。
- 实体呈长尾分布,识别尾部的实体效果不稳定。
- 缺少人工标注数据,从0搭建一个实体识别框架。
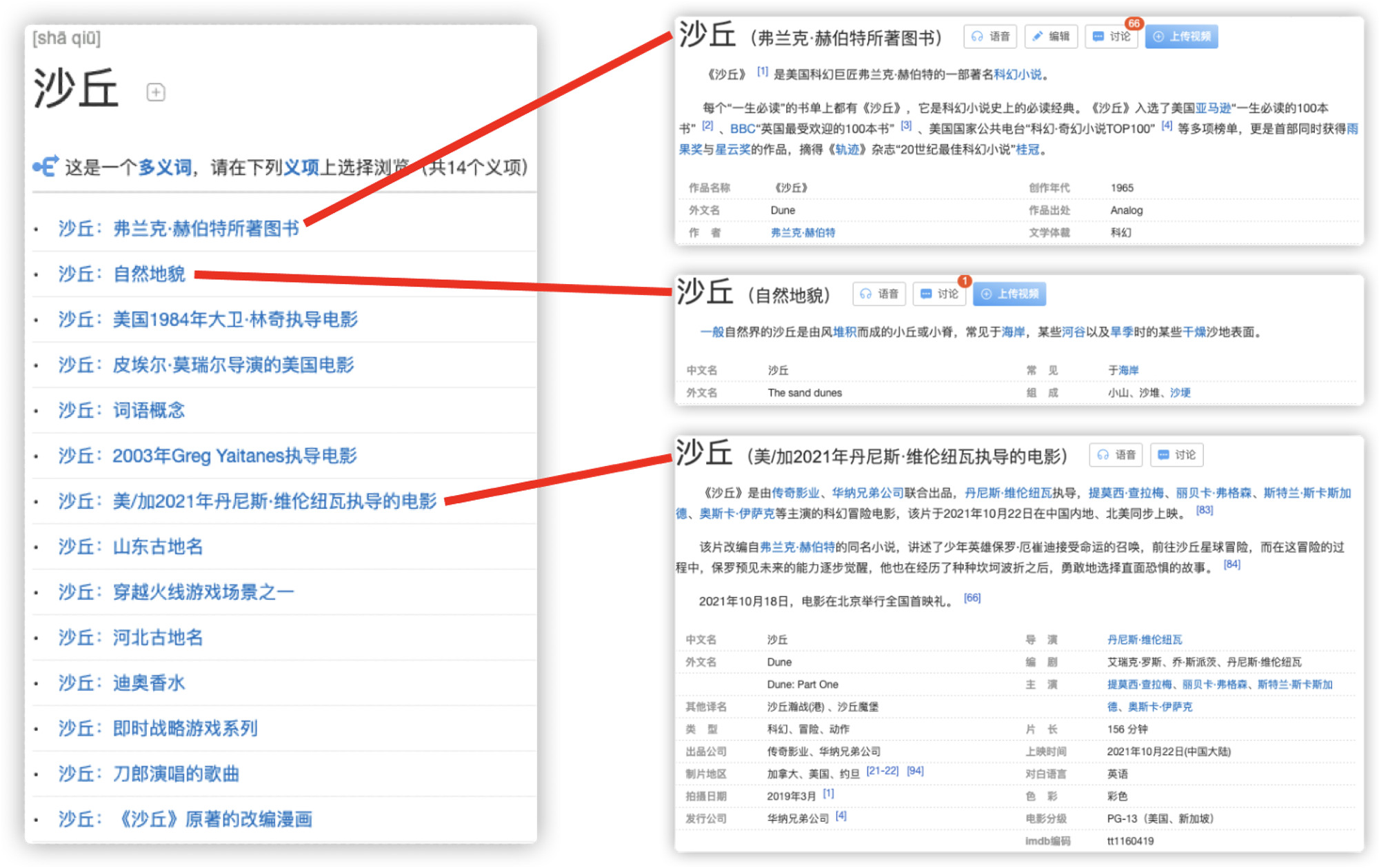
电影没理清的细节,都在《沙丘》原著小说里。;#英文原著阅读 #英文小说 #沙丘 年度最强科幻片,天选之子的复仇之路。#沙丘#电影 #60秒学英语;你想成为《沙丘》里的少年吗? #沙丘#沙丘预告片 神级摄影,神级配乐,科幻本幻,史诗本诗。#沙丘 新疆"死亡之海"沙丘连绵 沙漠探险自驾游渐热 自然地貌 影视 小说
以上面的“沙丘”为例,这个词在不同的语境中有不同的含义,可以代表小说、影视作品以及自然地貌。如何根据上下文对实体进行消歧,对模型识别精度的提升起着关键作用。
总体方案
针对以上挑战,我们在总体的技术方案有两个阶段,即实体识别和实体消歧。其中实体识别是从自然语言中抽取出候选命名实体列表;而实体消歧模块则是在给定命名实体及其上下文的情况下,在知识库中找到该命名实体所表示的实体,以确定实体的真实含义。
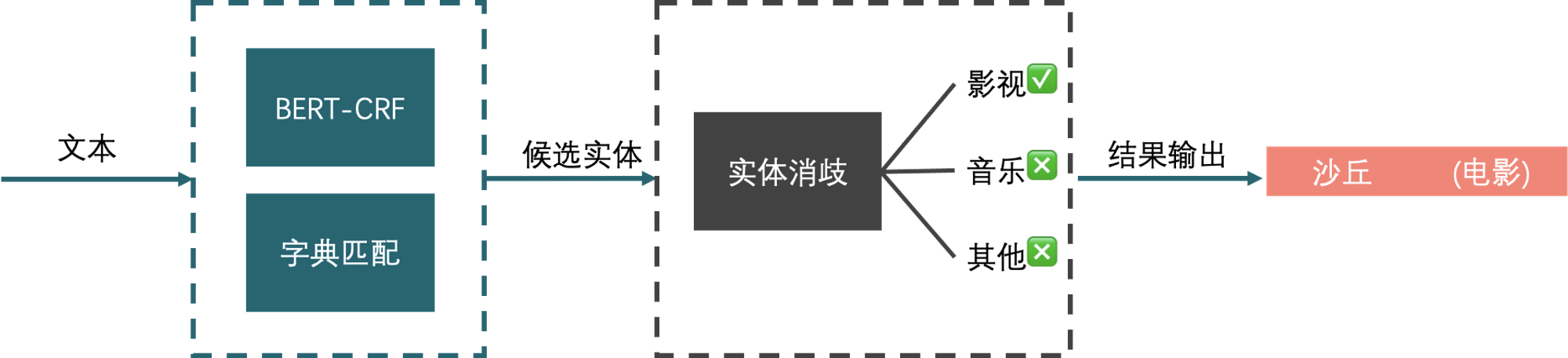
实体词典匹配
针对视频号的作品的特点,我们的在实体识别模型技术选型是实体词典匹配+模型预测,两者各自的特点在识别实体时可以互补。对于垂直领域,使用领域词典匹配是一快速且有效的启动方案,因为实体词典匹配具有以下特性:
- 相比于模型预测,实体词典匹配速度极快。
- 在垂直领域具有高召回率。尤其是在视频号作品场景中,用户通常会在标题中用“#”前缀给作品打上标签。通常标签串在语法上和上下文关联较弱,有时候甚至破坏标题的语法结构,再加上训练样本中大部分的标签串为非目标实体,造成模型在召回不佳,而词典匹配能够缓解这个问题。
- 保证识别结果有意义。使用实体词典过滤能够保证模型预测结果是与目标领域有一定的相关性,减少产生与目标领域无关的候选实体。
- 灵活可配置。对于新增的业务,可以通过增加词表方式进行适配。
弱监督NER模型
词典匹配虽然有速度快、高召回、可配置的优点,但其缺点也很明显,即无法解决候选实歧义性问题。举个例子,词典匹配产生的候选实体“沙丘”可能指弗兰克·赫伯特所著图书、自然地貌、电影《沙丘》。而模型预测会结合上下文,不会把“新疆"死亡之海"沙丘连绵 沙漠探险自驾游渐热”中的“沙丘”识别为影视实体。然而,训练处一个鲁棒的深度学习模型需要一定量级的训练样本,本章节提供了一个从0训练出垂直领域NER模型的迭代思路。
数据集构造
本节介绍在无人工标注数据的情况下,从0开始训练一个NER模型,思路可以总结成以下步骤:
首先,我们需要构建一个领域实体词典,然后通过词典匹配的方式构造一批粗糙的数据集。我们主要通过利用其他视频平台的搜索引擎或者使用词典匹配已经积累的垂类库,把每个实体的搜索结果加入到数据集。
接着过滤出高置信度的样本。方式主要有两个:
1) 通过实体固定的上下文进行筛选。影视、音乐类的一般会有书名号或其他的固定搭配,我们可以根据此特点是对数据集进行清理。这种方式构造的样本缺乏多样性,训练出来的模型很容易过拟合,因此训练时需要对实体固定的上下文做随机删除、插入、替换的数据增强。

2) 观察实体名字长度越长,实体的歧义越小,因此可以选择抛弃长度短且无固定上下文搭配的匹配结果;下图是用“速度与激情9”和“活着”匹配获得的样本,可见前者的样本质量更高。但这种方式构造的数据集会引入实体长度的偏差,对于一些较短的实体很难覆盖到。针对这种情况,可以引入实体随机替换,以消除实体长度对模型产生的影响,同时也能消除实体的长尾效应。

模型设计
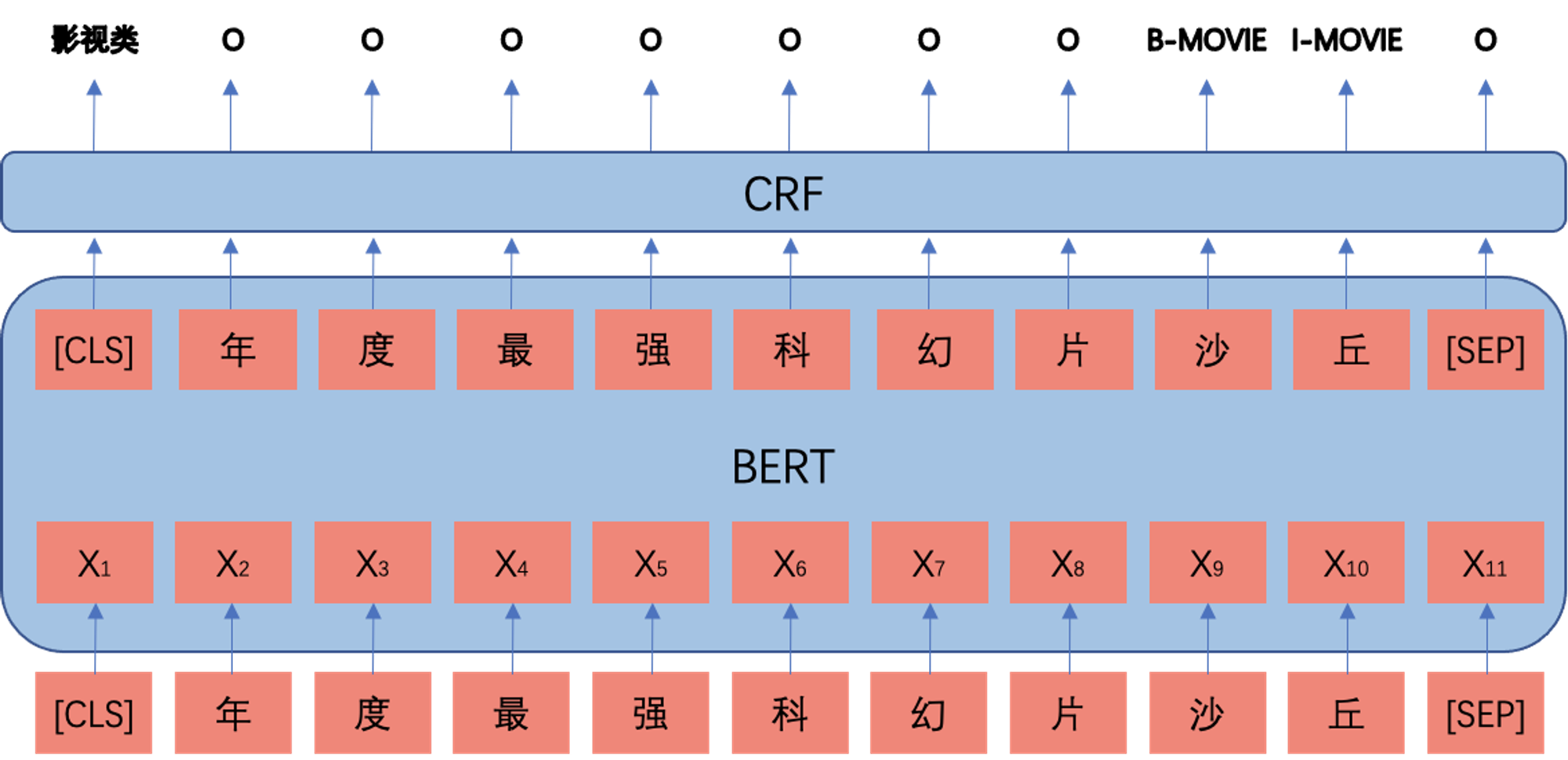
有了第一批相对高质量的样本,之后的任务就是训练出第一个版本的的NER模型,并不断优化性能。在选型方面,由于实体识别是NLP的一个相对成熟的任务,最近基于BERT的模型在性能上已经能取得较好的效果,我们选择目前相对成熟的BERT+CRF序列标注模型,至于BERT模型和CRF的原理不在本文的讨论范围之内,想了解的小伙伴可以看网络上的一些关于BERT和CRF文章。
近几年也有很多在对话领域的研究发现意图检测和实体识别是两个相互促进的任务,因为两者都是与垂直领域相关的;因此我们也引入领域分类与实体识别联合训练,并采用大规模性非目标领域的数据作为负样本加入到模型训练中。实体识别关注的是实体附近上下文局部特征,而领域分类关注的是句子的全局特征,联合学习有助于模型从不同角度处理信息。
在测试阶段,我们采用先标注,再分类的二阶段模型。在序列标注阶段,模型把影视、音乐、书本类统一标注为作品;在分类阶段,根据领域字典是匹配成功、领域分类结果和实体链接进一步判断。如果标注阶段采用细分的标签体系,对于只是覆盖率很高的文本,模型难以学习,如“韩寒《私奔》”(《私奔》是韩寒的音乐作品), “韩寒-《后会无期》”(《后会无期》是韩寒的电影作品),“韩寒的作品《三重门》”(《三重门》是韩寒的小说作品),同样是韩寒的作品,如果训练时采用三个不同的标签,没有知识融合的NER模型难免会难以收敛。
考虑到使用词典和规则构造的数据集会有漏标的情况。我们针对这种情况,我们采取两个方法减少实体标注不完全带来的影响。 我们通过引入Noise-Aware Loss (NAL)(参考论文[3]),当模型标注为实体且大于一定置信度,但标签为非实体的那一部分(这一部分最有可能是被规则漏标注),向损失变大的方向优化。
最终的loss为
实体链接消歧
实体链接是将文本中提及的实体(mention)与其知识库中相应的实体(entity)链接起来的任务,以达到消除mention歧义的目的。本文中的实体链接指Linking-Only形式的实体链接,将上下文和mention作为输入,在知识库(KB)找到最匹配的实体。
领域知识库构造
构建知识库的目的是输入mention,知识库输出候选实体及其描述。针对目前的使用场景,我们只需要构建<mention, [(候选实体, 实体描述, 实体类型)]>的键值映射即可,其中实体类型采用TexSmart对其描述分类+规则修正的方案构建。而这个步骤百度百科已经帮我们做好了,我们只需对其结果进一步加工。为了方便在线检索和更新,我们采用Elasticsearch作为知识库的存储容器。
实体链接
我们在实体链接部分我们采用基于词袋TF-IDF实体排序方案,具体的可以表示为:
其中未登录词的TFIDF则采用人工预设值的代替。
此方法还具有以下优点:
- 快速且可解释。快速是因为词匹配比模型匹配的逻辑简单;可解释是因为可以直观的观察匹配的词,避免神经网络难调试的短板。
- 整个过程完全无监督,处理业务上新增的垂类无需重新建模。
- 可以直接与其他模态标签进行联动。目前视频理解的主流方案是对视频内容做细粒度的内容拆解,将图像,动作,人物,声音这些背景信息,通过 CV 、语音识别技术做标签化,并以文本的模态存储。基于词袋TF-IDF的方案可以可以直接和标签进行交互。
实验结果
主要结果
为了评测效果,我们人工标注了一个1600个样本的影视综测试集,下表是评测效果。
从结果来看,使用实体链接对实体识别的精度提升很大,特别是遇到小说改编的电影/电视剧,实体链接可以轻松的消除混淆。对数据集的优化能够改善模型总体的性能。
跨域迁移能力
同样,为了测试模型在音乐实体的效果,我们人工标注了一个1000个样本的影视综测试集用于测试。不同的是,我们分别测试了是否使用音乐样本的区别,如下表所示:
可以看出,在影视领域训练的模型,在测试时只要加上音乐类词典,就能有可观的精度,这体现了方案有一定的跨域迁移能力;加上音乐类样本到训练集中,精度上接近影视实体识别。
总结
本文介绍了垂直领域命名实体识别的无人工标注弱监督训练方案,以及一个轻量高效的实体消歧思路。目前只是针对作品类命名实体识别的尝试,以后将探索更多领域的命名实体识别通用方案。
参考
[1] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding, NAACL 2019
[2] Conditional Random Fields: Probabilistic Models for Segmenting and Labeling Sequence Data, ICML 2001
[3] Named Entity Recognition with Small Strongly Labeled and Large Weakly Labeled Data, ACL 2021
[4] Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling, Interspeech 2016
[5] BERT for Joint Intent Classification and Slot Filling, CoRR abs/1902.10909
[6] Neural Entity Linking: A Survey of Models Based on Deep Learning, CoRR abs/2006.00575
[7] Empirical Analysis of Unlabeled Entity Problem in Named Entity Recognition, ICLR 2021
[8] A Rigorous Study on Named Entity Recognition: Can Fine-tuning Pretrained Model Lead to the Promised Land?, EMNLP 2020
[9] 流水的NLP铁打的NER:命名实体识别实践与探索,知乎
- 作者:Ross
- 链接:https://ross.selfcoding.cn/article/weekly-ner
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
