type
Post
status
Published
date
Aug 2, 2022
slug
user-embedding
summary
随着网络世界的发展,越来越多人开始在直播平台上分享内容。对主播进行建模是一项有趣且有挑战性的任务。在视频号中,主播的行为是复杂且多模态的,复杂体现在主播有简介、历史发步过的短视频,也有直播的信息等;而多模态体现在主播的信息包括文字、图片、视频画面、音频、标签信息等。如何利用这些复杂的信息压缩成一个 n 维的向量是具有挑战性的。
tags
NLP
推荐系统
category
技术分享
icon
password
URL
前言
背景
随着网络世界的发展,越来越多人开始在直播平台上分享内容。对主播进行建模是一项有趣且有挑战性的任务。在视频号中,主播的行为是复杂且多模态的,复杂体现在主播有简介、历史发步过的短视频,也有直播的信息等;而多模态体现在主播的信息包括文字、图片、视频画面、音频、标签信息等。如何利用这些复杂的信息压缩成一个 n 维的向量是具有挑战性的。
应用场景
主播 Embedding 跟其他类型的 Embedding 相似,可以应用在常见的检索场景。以下是主播 Embedding 的使用场景例子:
- 相似主播检索:在运营和黑产场景,想要通过一个种子主播找出其相关的主播时候使用主播Embedding是非常高效的,这个有利于运营侧快速地找出相似的主播。
- 主播冷启动:推荐系统通过用户和物品的交互,来预测用为未来的行为和兴趣。但是当有新主播加入的时候,往往需要冷启动将新主播分发给最有可能对其有兴趣的用户,以产生有效的曝光。
- 主播打散/去重:内容相近的主播在Embedding向量空间中距离也相近,搭配聚类算法可达到相似主播去重和打散的效果。
方案
信息时代数据为王,当可以直接获得用户的点击行为的时候,训练一个主播 Embedding 不是一件困难的事情。然而,由于用户的点击行为是用户的隐私,很多情况下非业务方是无法获取到用户的点击日志的。作为替代,业务方可提供基于用户行为训练的主播 ID-Embedding,可以通过蒸馏的方式进行训练主播内容 Embedding。
自监督主播 Embedding
在无法获取任务与用户点击相关的信息之时,而因为标注难度和数量太大无法进行人工标注训练集的时候,使用自监督方式训练是一个有效的方案。
近年来出现了很多自监督训练的方案,其中 BERT 最广为人知,其通过 Mask Language Model (MLM) 和 Next Sentence Prediction (NSP) 两个预训练任务来建模。MLM是通过随机 Mask 句子中的一些字,用未被 Mask 的上下文预测被 Mask 掉的词,以学习句子的表示;而 NSP 是将两个句子拼接之后,判断两个是否是后面的句子是不是前句的下一句,以学习句子之间的相似信息。语言模型在大规模无标签语料库上进行预训练以强化很多下游任务,受预训练语言模型的启发,微软近年来提出了使用用户行为构建的预训练用户模型 PTUM,提出了Masked Behavior Prediction (MBP) 和 Next K Behaviors Prediction (NBP) 两个用户 Embedding 预训练任务。
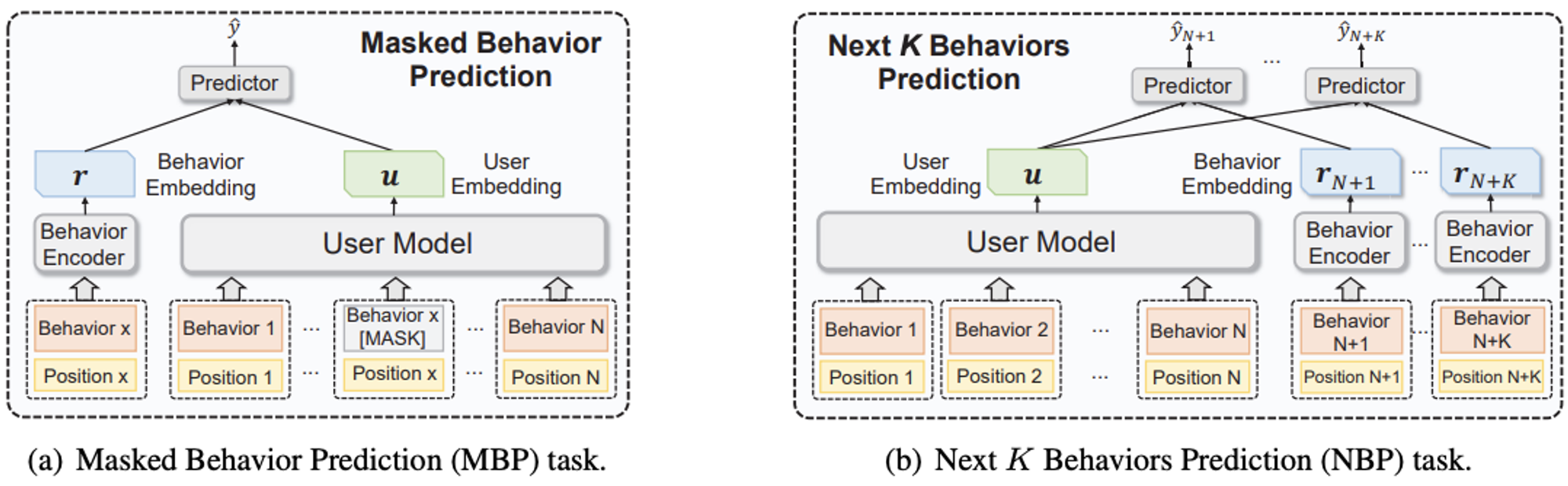
图1:PTUM 架构示意图
类似的,我们受到 PTUM 的启发,希望通过 Mask 的方式构造自监督的训练样本对,并通过对比学习进行无监督训练。但是由于应用场景包含多个模态,BERT / PTUM 这一类模型使用未被 MASK 的上下文预测 MASK 元素的 Embedding,在异构的输入上并不适用;因此我们利用对比学习的思想做了一些改造,将预测 MASK 元素的 Embedding 改为预测数据增强之后的主播 Embedding;数据增强采用随机 MASK 输入的方式,为了较少信息泄露,相同的主播可见信息的交集比例需要限制在较小的数值。
损失函数我们采用InfoNCE,同个 Batch 内相同的主播当做是正样本,不同主播之间是负样本。
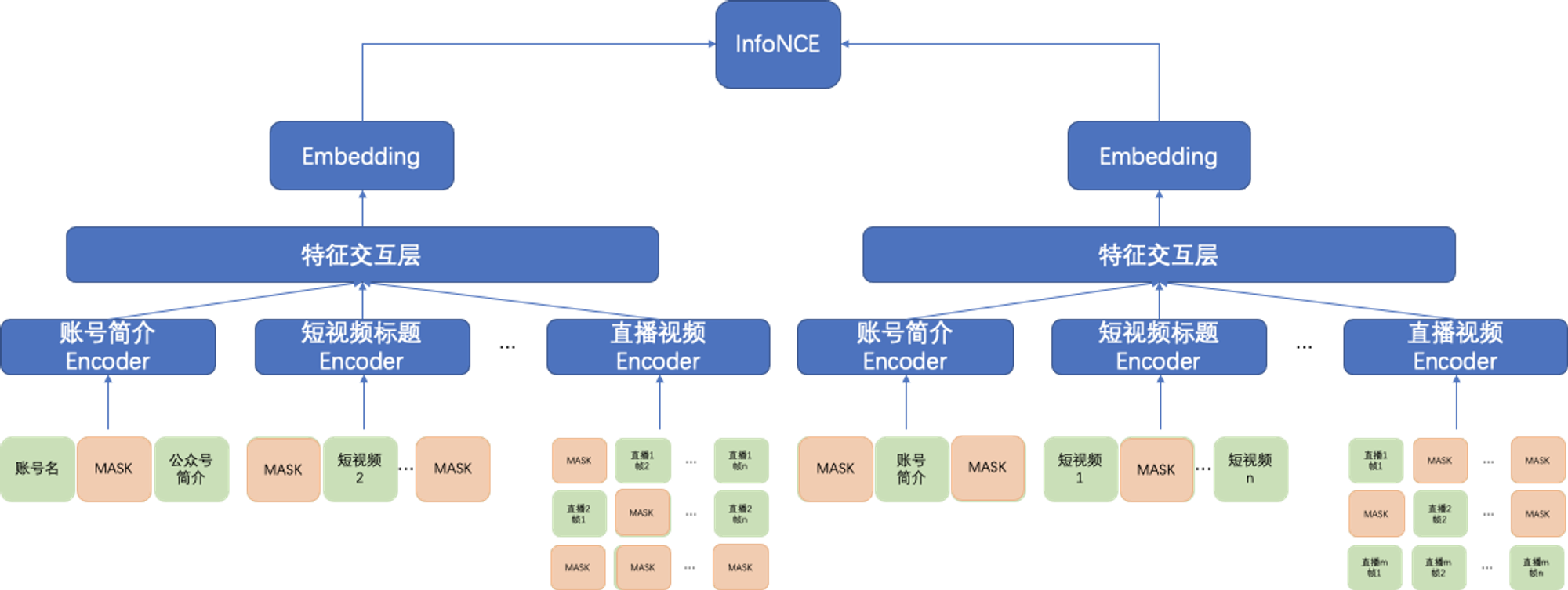
图2:主播 Embedding 对比学习框架
将信息从 ID-Embedding 迁移到主播内容 Embedding
ID-Embedding 是把用户和物品,并利用点击日志进行训练;而主播内容 Embedding 是通过主播的基本信息和历史行为(历史短视频以及直播)来构造画像。由于兴趣相同的用户一般会和相似的主播进行交互,例如喜欢 NBA 的用户与篮球类的主播交互更多,因此内容相似的主播在 ID-Embedding 的空间上也更加相近,我们希望通过将有用的信息从 ID-Embedding 迁移到主播内容 Embedding。下面将介绍两类已经实践过的知识迁移方式。
基于蒸馏的知识迁移
当只有 teacher 模型的输出( ID-Embedding) 没有 teacher 模型参数时,下面是一些参考的蒸馏方案参考:
- 最简单的方式自然是直接把 ID-Embedding 蒸馏到 student 模型的 feature map 上。
- 在 ID-Embedding 上采用聚类提取伪标签后,student 根据伪标签用分类的方式进行训练。
- 利用样本之间的关系进行蒸馏,比较经典的方案是 RKD loss,其利用一个 batch 内 ID-Embedding 构造相似度矩阵作为监督信息,让 student 模型学习样本之间的关系。
然而以上的蒸馏方式在存在两点不足:
- 抗噪能力差:如果 ID-Embedding 噪声较多,student 模型学习到的 Embedding 同样也有很多噪声。
- 不能充分利用预训练模型:由于是 feature map 层垮了领域,直接蒸馏的会把预训练模型已经学习到的知识破坏,需要在蒸馏过程中加入限制条件。
综上,teacher 模型的性能上限决定了 student 模型的性能上限,在跨域的情况下蒸馏信息也会磨损。
基于对比学习的知识迁移
为了解决直接蒸馏抗噪能力差和不好利用预训练模型的问题,我们采用基于检索构造正样本 + 对比学习进行知识迁移。其中基于检索构造正样本目的是为了数据降噪;对比学习是有监督与图2的结构一样,而正样本来自 query 样本和其相似召回的结果,负样本是 batch 内出自己之外的其他样本,整个训练过程在预训练模型上搭建,能够充分利用预训练模型的优势。
由于 ID-Embedding 是基于用户点击训练的,其相似性并非是内容语义相似,因此将 ID-Embedding 召回结果中不是内容语义相似的样本过滤,过滤的方式有很多种,包括计算编辑距离、利用相似模型计算相似度等方式。
与无监督的对比学习不同的是:有监督的对比学习能够获取困难正/负样本,任务的难度更大,模型在实际场景中使用的时候更鲁棒。
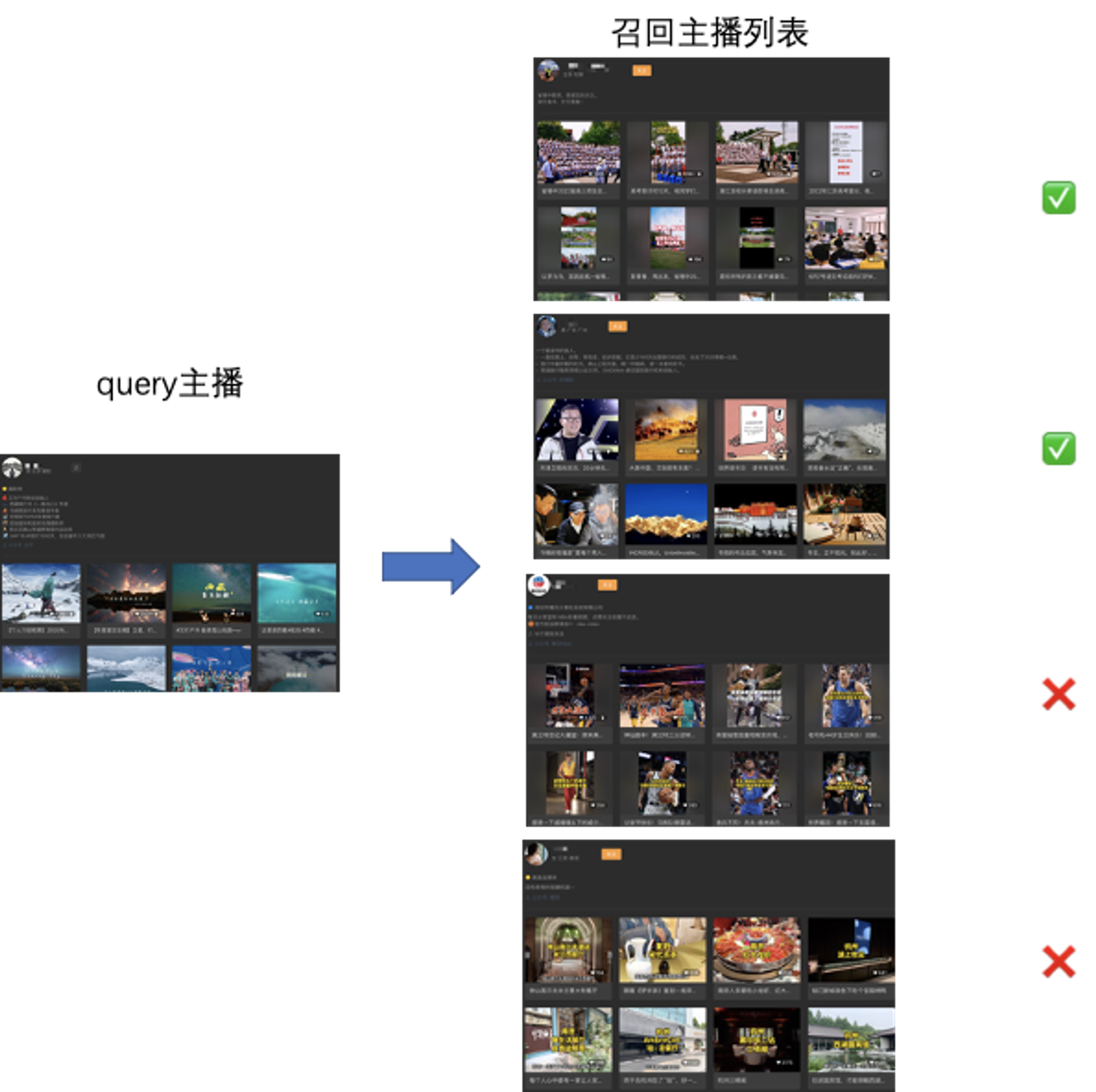
在真实的业务场景中,ID-Embedding 通常噪声比较多,而对比学习的知识迁移中整个数据清洗过程相对可控,训练过程也能很好的预训练模型的优势。
总结
本文探索了无用户点击数据的情况下构建主播 Embedding 的可能方案,实验对比了两类知识迁移的方式,基于对比学习的知识迁移的效果明显优于基于蒸馏的知识迁移,其中数据清洗的过程对最终效果影响较大。主播级别的 Embedding 可用的信息有很多,但 UGC 平台的数据的噪声也是很大,如何对数据降噪和精简显得格外重要;不仅需要处理模态缺失的问题,还要处理模态信息无意义使得召回效果不稳定的问题。未来,将探索更多的数据挖掘方式和模态交互的方案,以更好得描述用户代表的内容倾向。
参考文献
- Wu, C., Wu, F., Qi, T., Lian, J., Huang, Y., & Xie, X. (2020). PTUM: Pre-training user model from unlabeled user behaviors via self-supervision. Findings of the Association for Computational Linguistics Findings of ACL: EMNLP 2020, 1939–1944. https://doi.org/10.18653/v1/2020.findings-emnlp.174
- Gao, T., Yao, X., & Chen, D. (2021). SimCSE: Simple Contrastive Learning of Sentence Embeddings. EMNLP 2021 - 2021 Conference on Empirical Methods in Natural Language Processing, Proceedings, 6894–6910. https://doi.org/10.18653/v1/2021.emnlp-main.552
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of deep bidirectional transformers for language understanding. NAACL HLT 2019 - 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies - Proceedings of the Conference, 1, 4171–4186. https://doi.org/10.48550/arxiv.1810.04805
- Hinton, G., Vinyals, O., & Dean, J. (2015). Distilling the Knowledge in a Neural Network. https://doi.org/10.48550/arxiv.1503.02531
- Romero, A., Ballas, N., Kahou, S. E., Chassang, A., Gatta, C., & Bengio, Y. (2015, December 19). FitNets: Hints for thin deep nets. 3rd International Conference on Learning Representations, ICLR 2015 - Conference Track Proceedings. https://doi.org/10.48550/arxiv.1412.6550
- Park, W., Kim, D., Lu, Y., & Cho, M. (2019). Relational knowledge distillation. Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2019-June, 3962–3971. https://doi.org/10.1109/CVPR.2019.00409
- 作者:Ross
- 链接:https://ross.selfcoding.cn/article/user-embedding
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
