type
Post
status
Published
date
May 6, 2022
slug
summary
tags
NLP
category
技术分享
icon
password
URL
由于最近面试被文档 Transformer 结构的基础题,这边便简单地记录一下。
Encoder 和 Decoder的不同
首先需要贴一个图
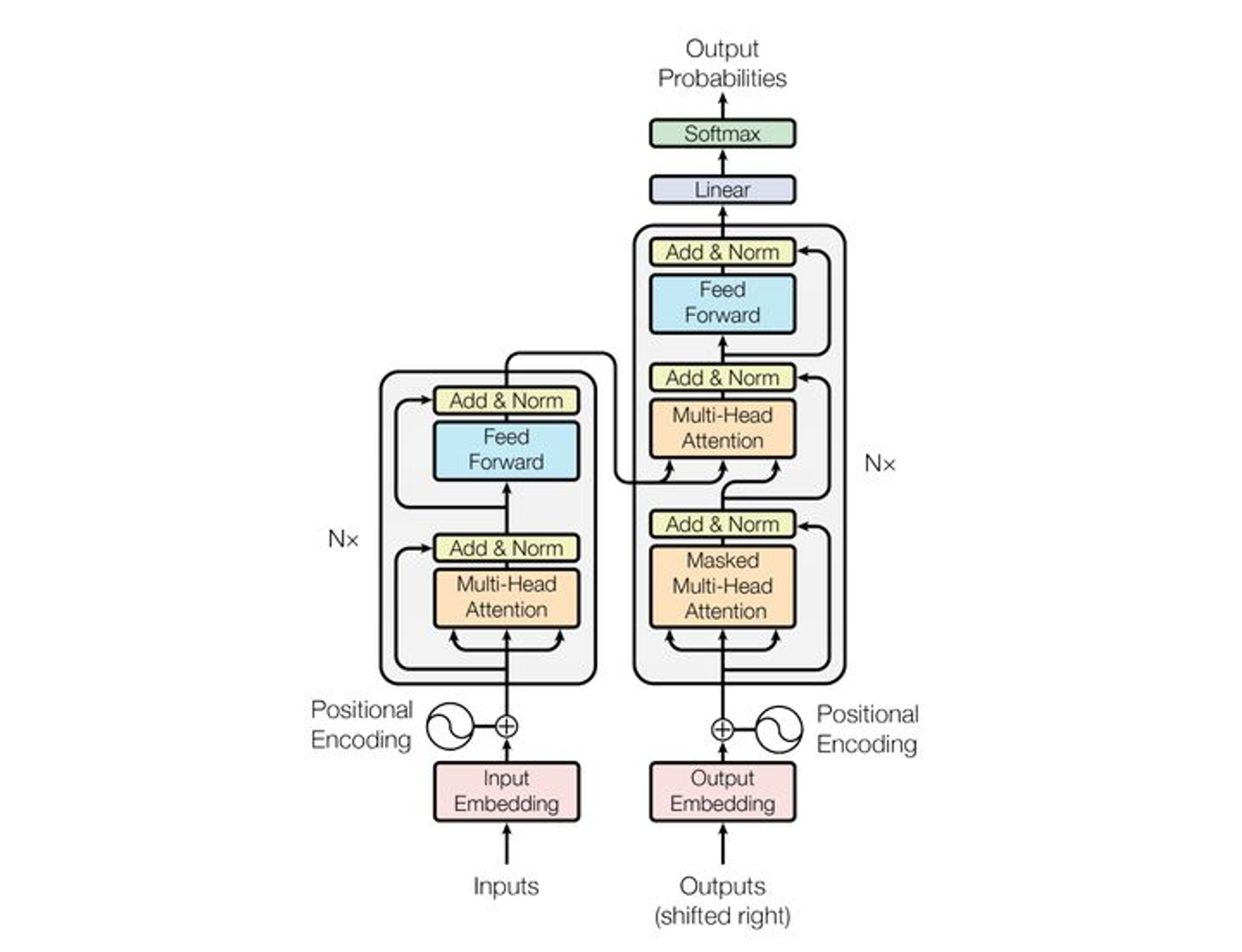
不同之处:
- 在 Encoder 的每一个 block 中只有一个 Multi-Head Attention 层,而 Decoder 有两个,而且中间的 Attention 不是自注意力层,为 K, V 来自Encoder 的输出,而 Q 来自前一个模块的输出。
- Mask 不同,Encoder 的是全局可见,而 Decoder 不能看见当前单词之后的。(是一个下三角方阵)
BERT 和 Transformer 位置编码的区别
- BERT是词汇表形式的Embedding,是一个 max_seq_len * hidden_size 的矩阵,是一个绝对位置编码。
- Transformer 是一个三角函数的形式的位置编码,计算 Attention 的时候可以表示相对位置。
i表示第i维,这样做是因为需要不同维度上应该用不同的函数操作位置编码,这样高位的空间表示才有意义。
相对位置编码的需求:
- 需要体现同一单词在不同位置的区别。
- 需要体现一定的先后次序,并且在一定范围内的编码差异不应该依赖于文本的长度,具有一定的不变性。
- 需要有值域的范围限制。
WordPiece 预处理
WordPiece字面理解是把 word 切开。
实现这个功能的算法叫 BPE (Byte-Pair Encoding)双字节编码。
训练过程:
首先将词分成一个一个的字符,然后在词的范围内统计字符对出现的次数,每次将次数最多的字符对保存起来,直到循环次数结束。
用处
- 较少词表
- 过滤低频的词,模型更好学
- 时态之间语义关联更强
- 作者:Ross
- 链接:https://ross.selfcoding.cn/article/2650bde9-6d7c-4ea3-8a5e-5800579051f4
- 声明:本文采用 CC BY-NC-SA 4.0 许可协议,转载请注明出处。
